世界の大規模言語モデル市場の規模、シェア、成長予測、2025 – 2032

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
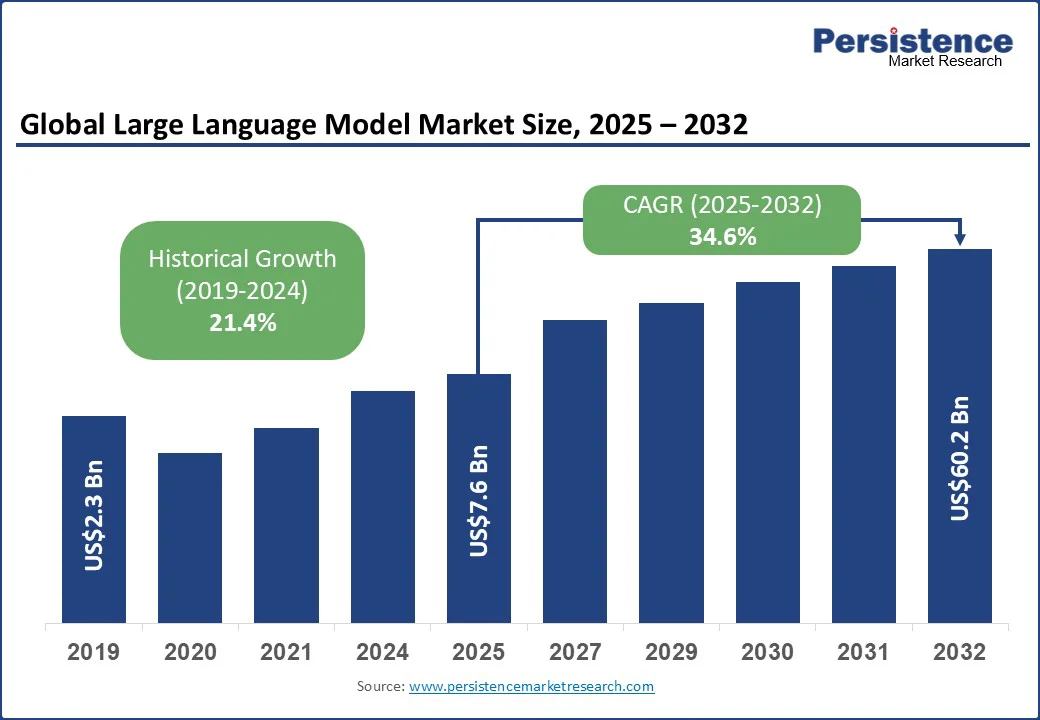
大規模言語モデル市場の調査報告書によると、2025年における市場規模は76億米ドルと予測され、2032年には602億米ドルに達する見込みであり、2025年から2032年までの間に年平均成長率(CAGR)は34.6%に達するとされています。この市場の成長は、企業が自動化、意思決定、個別対応を目的にAIを活用する中で急速に進んでいます。デジタル化の進展とインテリジェントなエンゲージメントに対する需要の高まりが、チャットボットやバーチャルアシスタント、カスタマーサービスにおける採用を加速させています。企業はこれらのシステムを利用して生産性を向上させ、コストを最適化し、イノベーションを加速させています。
生成AIの導入が進む中で、コンテンツ作成、顧客エンゲージメント、ソフトウェア開発、データ分析などの分野で高度な大規模言語モデルへのニーズが高まっています。企業はこれらのモデルを採用することで効率性の向上、ワークフローの自動化、意思決定の強化を図っており、より強力でスケーラブルなソリューションへの需要を促進しています。この急速な拡大は、大規模言語モデルを各業界におけるデジタルトランスフォーメーションの中核的な推進要因として位置付けています。
しかしながら、大規模言語モデルのバイアスは、訓練に使用されるデータセットに起因しています。これらのデータセットはしばしば歴史的な偏見やステレオタイプ、性別、人種、文化の不均等な表現を反映しています。特定の視点に偏った訓練データでは、モデルが支配的な視点を優遇したり、周縁化されたグループを誤って表現したりする傾向があります。このような公平性や包括性を損なう問題は、AIシステムが膨大だが不完全なデータソースに依存している構造的な限界を浮き彫りにしています。2024年に行われた研究では、GPT-4oやGemini 1.5 Pro、Claude 3 Opus、LLaMA 3 70Bなどの主要モデルにおいて、職業役割表現における性別バイアスが最大37%、犯罪関連のプロンプトに対する応答において人種的偏りが54%も見られることが明らかになりました。これらの結果は規制当局の注目を集めています。
大規模言語モデルの専門的な訓練は、医療記録や法的文書、財務報告書などのドメイン特化型データセットを使用することで、より正確で文脈を考慮したアプリケーションを可能にします。ファインチューニングは、特定のアプリケーションに合わせて事前に訓練されたモデルを洗練させる手法であり、顧客サポートやコンプライアンス監視、多言語コミュニケーションなどの用途に利用されます。具体的には、2024年に導入されたLoRAやQLoRAなどのパラメータ効率的ファインチューニング(PEFT)手法は、選択されたパラメータのみを更新することでコストを削減し、モデルのコア知識を保持することができます。
大規模言語モデルの開発者は、人間のフィードバックを取り入れた強化学習(RLHF)を統合することで、責任あるAIプラクティスを優先しています。これにより、人間の価値観への整合性を高め、有害な出力を最小限に抑えることができます。たとえば、DeepMindは公表された倫理フレームワークを通じて公平性と透明性を強調し、OpenAIはGPT-4のモデル行動を人間のフィードバックを元に改善しています。これらの取り組みは、AIシステムに対する信頼と責任を構築する重要性が高まっていることを反映しています。
市場は、提供内容に基づいてソフトウェアとサービスにセグメント化されます。これらの中で、ソフトウェアセグメントは2025年に65%以上の市場シェアを占めると予測されています。この成長は、基盤となるモデルやAPIベースのソリューションの迅速な展開と広範なアクセス可能性によるものです。たとえば、OpenAIの有料ビジネスユーザーは、6月の300万人から8月には500万人に増加し、AIソフトウェアへの企業や教育機関の支持の高まりを示しています。企業はこれらのソフトウェアツールを利用して生産性を向上させ、業務を効率化し、スケーラブルな展開をサポートしています。
サービスセグメントも、AIの統合やカスタマイズ、展開支援に対する需要の増加により、重要な成長が見込まれています。企業はAIソリューションの実装、最適化、メンテナンスのために専門的なサービスを求めており、これにより生産性と業務効率が向上します。クラウドベースやハイブリッドAI環境の普及により、シームレスな展開とスケーラビリティを保証するための専門的なサービスの需要が高まっています。
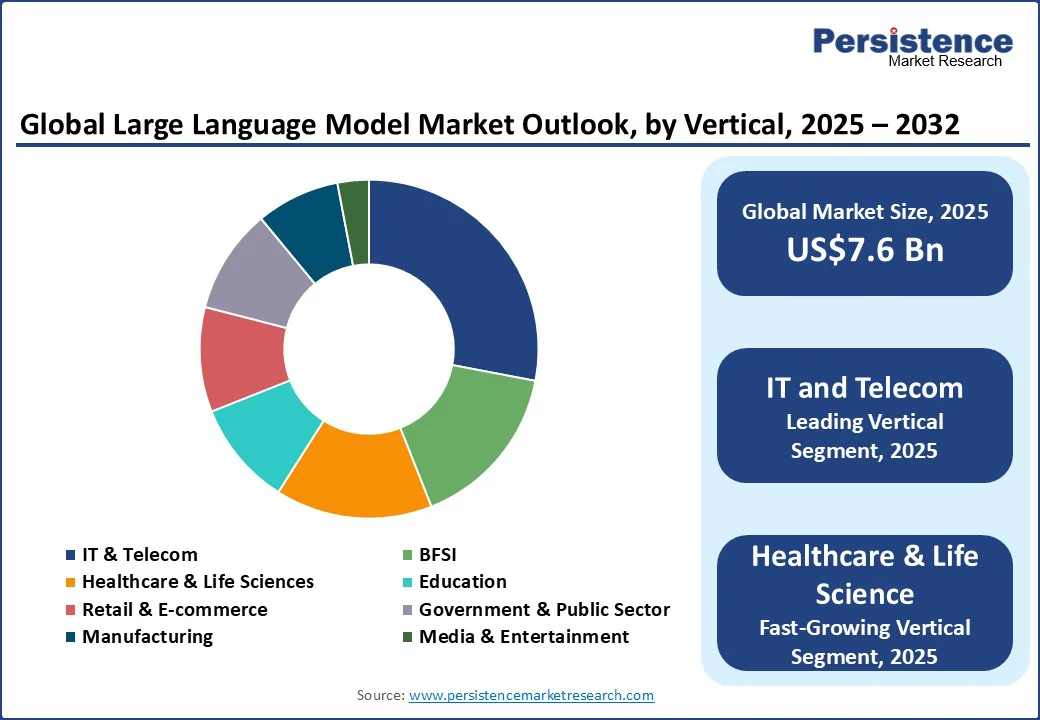
市場はさらに、IT・通信、BFSI(銀行、金融サービス、保険)、ヘルスケア・ライフサイエンス、教育、小売・eコマース、政府・公共部門、製造業、メディア・エンターテインメント、その他にセグメント化されています。2025年には、IT・通信セグメントが28%以上のシェアを占めると予測されており、これは自動化、リアルタイム通信、高度なデータ処理に対する需要の高まりによるものです。特に通信会社は、AIチャットボットを活用して顧客サービスを向上させ、予測分析を通じてネットワークパフォーマンスを最適化し、個別化された体験を提供しています。2024年のNVIDIAの調査によると、通信プロバイダーの約90%がAIを業務に統合しており、業界の急速な採用が示されています。
ヘルスケア・ライフサイエンスセクターも、効率的なデータ分析、個別化された患者ケア、薬剤発見の加速に対する需要の高まりにより、重要な成長が期待されています。大規模言語モデルを活用した医療研究、診断、自動文書化は、業務の効率性とイノベーションを向上させています。ある研究によると、ChatGPTは患者の歴史や身体検査に基づいて60.3%の精度で鑑別診断を生成する能力を示しており、その臨床的重要性が高まっています。
北米地域は、2025年に34%以上のシェアを占めると予測されており、これは堅牢な技術インフラ、AI研究への重要な投資、先進的なAI企業の存在によるものです。アメリカ合衆国にはOpenAI、Google、Microsoft、Metaなどの主要なプレイヤーがあり、これらの企業はGPT-4、Gemini、Llamaなどの先進的な大規模言語モデルの開発をリードしています。これらの組織は、大規模な計算リソース、才能のプール、資金へのアクセスを享受しており、AIの能力の限界を押し広げることができます。国立科学財団(NSF)や国防総省(DoD)などの政府の支援が、AI研究への資金提供や取り組みの設立を通じて、大規模言語モデルの開発を加速させています。
アジア太平洋地域は、政府の投資の増加、インフラの拡大、官民パートナーシップ、地域モデル開発の活発化、スタートアップエコシステムの発展により、2025年に最も急成長する地域となる見込みです。シンガポールでは、IMDA、A*STAR、AI Singaporeによって立ち上げられた7000万米ドルの国家マルチモーダル大規模言語モデルプログラム(NMLP)が、地域の言語と文化的文脈に合わせた初のマルチモーダル大規模言語モデルエコシステム、SEA-LIONの構築を目指しています。この取り組みは、大規模言語モデルの研究開発を加速し、国産モデルの展開を可能にし、地域の才能を育成することで、シンガポールを2024年のAIイノベーションのハブとして位置付けます。
中国は新世代人工知能発展計画や膨大なデジタルデータ、Baidu、Alibaba、Tencent、Huaweiなどのテクノロジー大手に支えられ、研究開発において優位性を持っています。Huaweiが2024年中頃にリリースしたパングΣは、1兆以上のパラメータを持ち、この成長を体現しています。2024年中頃までに中国には約2億3000万人の生成AIユーザーが存在し、大規模な商業利用が進んでいます。企業はこれらのモデルを活用してチャットボットやバーチャルアシスタント、データ駆動型意思決定を強化しており、IT、通信、eコマース分野での拡大がAI駆動型言語ソリューションへの強い需要を生み出しています。
ヨーロッパは、大規模言語モデルにとって戦略的なハブであり、倫理的AIガバナンス、規制フレームワーク、堅牢な官民研究ネットワークに対する強いコミットメントがあります。EUのAI法は透明性、安全性、人間の監視を確保し、AI導入の信頼できる環境を創出しています。ドイツ、フランス、オランダなどの国々は国家AI戦略を打ち出し、Fraunhofer InstitutesやINRIAなどの研究センターに資金を提供して大規模言語モデルにおけるイノベーションを支援しています。需要は、ヨーロッパの多言語人口、企業のデジタル化、学界と産業の協力によってさらに促進されています。Horizon Europeなどのプログラムは、950億ユーロ(約1030億米ドル)を超える予算を持ち、CLAIRE(ヨーロッパのAI研究のためのラボ連合)やELLIS(学習と知的システムのためのヨーロッパラボ)などのイニシアティブも基盤となるAI研究と展開を強化しています。
大規模言語モデルは、言語翻訳、バーチャルアシスタント、カスタマーサービスの自動化にますます必要とされており、ヨーロッパを責任あるスケーラブルなAIソリューションのリーダーとして位置付けています。大規模言語モデル市場は、ニッチなスタートアップの断片的な空間から、主要なテクノロジー大手が小規模プレイヤーを買収したり追い越したりすることで、より統合された風景へと移行しています。主要なプロバイダーの数は、経済的な圧力や統一されたプラットフォームへの需要の高まりに伴い、今後数年で減少する見込みです。企業はこのシフトを推進するために、買収、オープンソースプログラム、戦略的パートナーシップ、インフラの管理を通じて、スケーラブルで統合されたAIソリューションを提供し、導入を簡素化し企業価値を向上させています。
大規模言語モデル市場は2025年に76億米ドルの価値が見込まれています。AIによる自動化の進展、高度なデータ分析、業界全体における個別化されたデジタル体験が主要な推進要因です。大規模言語モデル市場は、2025年から2032年にかけてCAGR34.6%を記録する見込みです。特定のドメインにおける専門知識や多言語対応の需要が急増しており、大きな機会を提供しています。OpenAI、Google、Anthropic、Microsoft、Meta、Amazon Web Services(AWS)、IBM Corporation、Cohere、Mistral AI、Stability AI、NVIDIAなどが主要なプレイヤーとして名を連ねています。
Report Coverage & Structure
エグゼクティブサマリー
このセクションでは、大規模言語モデル市場の2025年と2032年のスナップショットを提供し、市場の機会評価や主要な市場トレンドを分析します。市場機会評価では、2025年から2032年にかけての市場規模を米ドル(US$ Bn)で評価し、主要な市場トレンドや業界の発展、重要な市場イベントを取り上げます。また、需要側と供給側の分析も行い、PMR分析や推奨事項を通じて、今後の市場展望に関する洞察を提供します。
市場概況
市場概況セクションでは、大規模言語モデル市場の範囲と定義を明確にし、バリューチェーン分析を行います。マクロ経済要因としては、世界のGDP見通し、デジタルトランスフォーメーションとICTの浸透、AIインフラへの投資、インフラ投資、金融セクターの革新が含まれ、これらが市場に与える影響を考察します。また、予測要因の関連性と影響、COVID-19の影響評価、PESTLE分析、ポーターのファイブフォース分析、地政学的緊張が市場に与える影響、規制および技術の状況を詳述します。
市場動向
このセクションでは、大規模言語モデル市場のドライバー、制約、機会、およびトレンドを分析します。市場を推進する要因や、成長の妨げとなる要因を特定し、今後の機会を示唆するトレンドを浮き彫りにします。
価格動向分析
価格動向に関する分析では、製品やサービスの提供に基づく価格の傾向を探り、価格に影響を与える要因を詳述します。これにより、価格設定の戦略や市場における競争のダイナミクスを理解する手助けとなります。
大規模言語モデル市場の見通し
このセクションでは、2019年から2024年までの歴史的データと、2025年から2032年までの予測を基に市場の見通しを示します。提供別、展開モード別、モダリティ別、アプリケーション別、業種別の市場規模を分析し、各セグメントの魅力を評価します。また、ソフトウェアやサービス、オンプレミス、クラウドベース、ハイブリッド、テキスト、コード、画像、動画、チャットボットや仮想アシスタント、コンテンツ生成、コード生成やソフトウェア開発、顧客サービスの自動化、言語翻訳やローカリゼーションなどの各アプリケーションが市場に与える影響を詳しく解説します。
地域別の市場展望
地域別の市場展望では、北米、ヨーロッパ、東アジア、南アジアおよびオセアニア、ラテンアメリカ、中東およびアフリカの市場サイズを分析し、各地域の特性と市場の魅力を評価します。各地域における主要国(アメリカ、カナダ、ドイツ、フランス、中国、インドなど)の市場予測も含まれ、地域特有の動向や機会が明らかにされます。
競争環境
競争環境セクションでは、2024年の市場シェア分析を行い、市場構造や競争の強度をマッピングします。競争ダッシュボードを用いて、市場の主要プレーヤーについての情報を提供し、各社の戦略や開発状況を概観します。特に、OpenAI、Google、Anthropic、Microsoft、Meta、Amazon Web Services(AWS)、IBM、Cohere、Mistral AI、Stability AI、NVIDIAなどの企業プロフィールが詳細に記載されており、各社の製品ポートフォリオ、財務状況、SWOT分析が含まれています。
*** 本調査レポートに関するお問い合わせ ***

大規模言語モデル(だいきぼげんごモデル)とは、膨大なテキストデータを基にして訓練された人工知能(AI)の一種で、自然言語処理(NLP)において非常に高い性能を発揮するモデルです。これらのモデルは、文脈を理解し、言語を生成する能力があり、特に人間の言語のニュアンスや構造を捉えることに優れています。大規模言語モデルは、通常数十億から数兆のパラメータを持ち、データの質と量がその性能に大きく影響します。
大規模言語モデルには、いくつかの異なる種類があります。例えば、トランスフォーマーアーキテクチャに基づいたモデルが広く使用されており、これにはOpenAIのGPTシリーズやGoogleのBERT、T5などが含まれます。これらのモデルは、文の生成や要約、翻訳、質問応答など様々なタスクに対応できるため、非常に多用途です。また、特定の分野に特化したモデルも存在し、医療、法律、技術などの専門的な知識を持つモデルも開発されています。
大規模言語モデルの利用方法は多岐にわたります。ビジネスの分野では、カスタマーサポートの自動化や、コンテンツ生成、データ分析に活用されています。教育分野では、学習支援ツールや個別指導のアシスタントとして利用され、学生の理解を深める手助けをしています。また、クリエイティブな領域では、文章や詩の生成、ストーリーの構築などにも使われており、アートと技術の融合が進んでいます。
さらに、大規模言語モデルは関連技術と密接に結びついています。例えば、機械学習や深層学習は、これらのモデルの基盤技術として重要な役割を果たしています。また、データ収集や前処理、モデルのトレーニング環境の設定など、多くの技術的な側面が必要です。最近では、モデルの公平性や倫理に関する研究も進められており、バイアスを軽減し、より良い結果を得るための取り組みが行われています。
これらの特性により、大規模言語モデルは今後の技術革新において非常に重要な役割を果たすと考えられています。言語理解の精度が向上することで、より自然なコミュニケーションが可能になり、さまざまな業界での効率化や新しいサービスの創出につながることでしょう。大規模言語モデルの進化は、私たちの生活や仕事のあり方を大きく変える可能性を秘めています。