世界の科学データ管理市場:提供形態別(サービス、ソフトウェア)、データタイプ別(ゲノム、イメージング、メタボローム)、導入形態別、エンドユーザー別 – グローバル予測 2025年~2032年

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
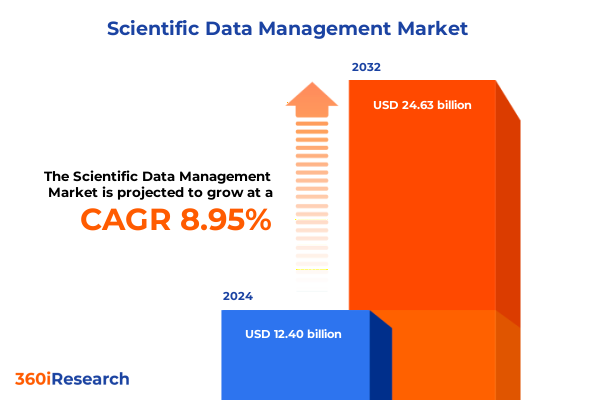
科学データ管理市場は、2024年に124億ドルと推定され、2025年には133.3億ドルに達すると予測されています。その後、年平均成長率(CAGR)8.95%で成長し、2032年には246.3億ドルに達する見込みです。今日の研究集約型環境では、データ量、複雑性、速度が前例なく急増しており、堅牢で統合された科学データ管理戦略が不可欠です。ハイスループットシーケンシング、イメージングモダリティ、マルチオミクスアッセイから生成される膨大な生データを、一貫性のある実用的な洞察へと変換するニーズはかつてないほど高まっています。本レポートは、高度なデータ管理ソリューション採用の主要因を概観し、効果的なガバナンス、スケーラブルなインフラストラクチャ、インテリジェントな分析が学術・商業環境における競争優位性維持の中心であることを示します。調査範囲は、マネージドサービス、プロフェッショナルサービスから、データストレージ、分析、ラボインフォマティクス、可視化のための最先端プラットフォームまで多岐にわたります。また、変革的な市場変化の分析、最近の貿易政策の累積的影響の定量化、技術調達とプロセス最適化を形成するセグメンテーションと地域的ニュアンスの解明を目的としています。
以下に、提供された情報に基づき、日本語に翻訳された詳細な目次を構築します。
—
## 目次
**序文**
* 市場セグメンテーションと範囲
* 調査対象年
* 通貨
* 言語
* ステークホルダー
**調査方法**
**エグゼクティブサマリー**
**市場概要**
**市場インサイト**
* リアルタイムデータインサイトのためのAI搭載ラボ情報システムの導入
* 実験の完全性を確保するためのブロックチェーン対応データ来歴ソリューションの採用
* 継続的なサンプル監視のためのIoTセンサーとLIMSプラットフォームの統合
* 大規模ゲノミクスおよびプロテオミクス研究に最適化されたクラウドネイティブデータレイクの登場
* データの一元化なしに機関横断的なコラボレーションを促進するためのフェデレーテッドデータモデルの実装
* 実験データセット向け自然言語処理による自動メタデータタグ付けの進展
* ソース機器の近くでハイスループットシーケンシングデータを処理するためのエッジコンピューティングインフラストラクチャの展開
**2025年の米国関税の累積的影響**
**2025年の人工知能の累積的影響**
**科学データ管理市場、提供タイプ別**
* サービス
* マネージドサービス
* プロフェッショナルサービス
* ソフトウェア
* データ分析プラットフォーム
* データストレージ&管理ソフトウェア
* ラボ情報ソフトウェア
* 可視化ツール
**科学データ管理市場、データタイプ別**
* ゲノム
* DNAシーケンシングデータ
* RNAシーケンシングデータ
* イメージング
* 顕微鏡データ
* MRIデータ
* X線データ
* メタボローム
* フラックス解析データ
* メタボライトプロファイリングデータ
* プロテオーム
* 質量分析データ
* プロテインマイクロアレイデータ
**科学データ管理市場、展開モード別**
* クラウド
* ハイブリッドクラウド
* プライベートクラウド
* パブリッククラウド
* オンプレミス
* 永続ライセンス
* 期間ライセンス
**科学データ管理市場、エンドユーザー別**
* 学術研究機関
* バイオテクノロジー企業
* 臨床検査機関
* 受託研究機関
* 政府機関
* 製薬会社
**科学データ管理市場、地域別**
* アメリカ大陸
* 北米
* ラテンアメリカ
* 欧州、中東、アフリカ
* 欧州
* 中東
* アフリカ
* アジア太平洋
**科学データ管理市場、グループ別**
* ASEAN
* GCC
* 欧州連合
* BRICS
* G7
* NATO
**科学データ管理市場、国別**
* 米国
* カナダ
* メキシコ
* ブラジル
* 英国
* ドイツ
* フランス
* ロシア
* イタリア
* スペイン
* 中国
* インド
* 日本
* オーストラリア
* 韓国
**競争環境**
* 市場シェア分析、2024年
* FPNVポジショニングマトリックス、2024年
* 競合分析
* サーモフィッシャーサイエンティフィック社
* ダッソー・システムズSE
* IBMコーポレーション
* オラクルコーポレーション
* マイクロソフトコーポレーション
* SASインスティチュート社
* パーキンエルマー社
* ウォーターズコーポレーション
* アジレント・テクノロジーズ社
* ブルカーコーポレーション
* バイオ・ラッド・ラボラトリーズ社
* イルミナ社
* キアゲンN.V.
* ラボバンテージ・ソリューションズ社
* アボット・ラボラトリーズ
* シーメンス・ヘルシニアーズAG
* GEヘルスケア・テクノロジーズ社
* マッケソン・コーポ
………… (以下省略)
*** 本調査レポートに関するお問い合わせ ***

科学データ管理は、現代の科学研究においてその重要性を飛躍的に高めている分野である。データ駆動型科学の時代において、研究活動によって生成される膨大な量のデータを、その価値を最大限に引き出し、信頼性、再現性、透明性を確保しつつ、効率的に収集、整理、保存、共有、再利用するための体系的なプロセスを指す。これは単なる技術的な課題に留まらず、研究の質と効率、ひいては科学全体の進歩を左右する戦略的な要素として認識されている。
現代科学が直面するデータ管理の課題は多岐にわたる。ゲノム解析、気候変動モデリング、素粒子物理学実験など、様々な分野で生成されるデータは、その量、種類、複雑性において爆発的に増加している。これらの「ビッグデータ」は、異なる形式や標準で生成されるため、統合や相互運用が困難である。また、長期的な保存における技術的陳腐化、セキュリティ、プライバシー保護、そして研究者個人のデータ管理能力の格差も、深刻な問題として浮上している。
このような背景から、科学データ管理の国際的な指針として「FAIR原則」が提唱されている。これは、データが「見つけられる (Findable)」、「アクセスできる (Accessible)」、「相互運用できる (Interoperable)」、「再利用できる (Reusable)」という四つの要素を満たすべきであるという考え方である。FAIR原則に則ったデータ管理は、データの発見可能性を高め、研究コミュニティ全体での共有と再利用を促進し、新たな知見の創出を加速させる上で不可欠な基盤となる。
具体的な実践としては、研究計画の初期段階でデータ管理計画(DMP)を策定することが推奨される。DMPは、データの生成から保存、共有、廃棄に至るライフサイクル全体を俯瞰し、メタデータ標準の適用、適切なデータリポジトリの選定、アクセス権限の設定などを明文化する。電子実験ノート(ELN)や専門的なデータ管理システム、クラウドコンピューティング技術の活用も、データの効率的な収集と整理、分析を支援する。さらに、人工知能(AI)や機械学習(ML)は、複雑なデータセットからのパターン抽出や自動分類において、その可能性を広げている。
科学データ管理は、研究者、研究機関、資金提供機関、出版社といった多様なステークホルダーが連携して取り組むべき課題である。各々の役割と責任を明確にし、倫理的側面(個人情報保護、インフォームドコンセント)や法的側面(知的財産権、データ主権)を遵守しつつ、データの価値を最大化するエコシステムを構築することが求められる。データの適切な管理は、研究の再現性を保証し、研究不正のリスクを低減する上でも極めて重要である。
この取り組みがもたらす恩恵は計り知れない。研究効率の向上、新たな発見の加速、学際研究や国際協力の促進はもとより、オープンサイエンスの実現を通じて、科学的知識の民主化と社会への還元を可能にする。例えば、パンデミック対応におけるゲノムデータや臨床データの迅速な共有は、その有効性を明確に示した事例である。
今後、科学データ管理は、ブロックチェーン技術によるデータの真正性保証や、より高度なAIを活用したデータキュレーションの自動化など、技術革新と共に進化を続けるだろう。研究者への継続的な教育と意識改革、そして国際的な標準化とインフラ整備の推進は、持続可能で強靭なデータエコシステムを構築するために不可欠である。
結論として、科学データ管理は、単なる研究の補助的な活動ではなく、現代科学の信頼性、効率性、そして革新性を支える中核的な柱である。その適切な実践は、未来の科学的発見を加速し、人類社会の持続可能な発展に貢献するための不可欠な要素となるだろう。