世界の自動音声認識ソフトウェア市場:技術別(機械学習型認識、深層学習型認識、自然言語処理(NLP))、導入形態別(クラウド型、オンプレミス型)、機能別、用途別、エンドユーザー産業別 – グローバル予測2025-2032年

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
## 自動音声認識ソフトウェア市場:詳細分析(2025-2032年)
### 市場概要
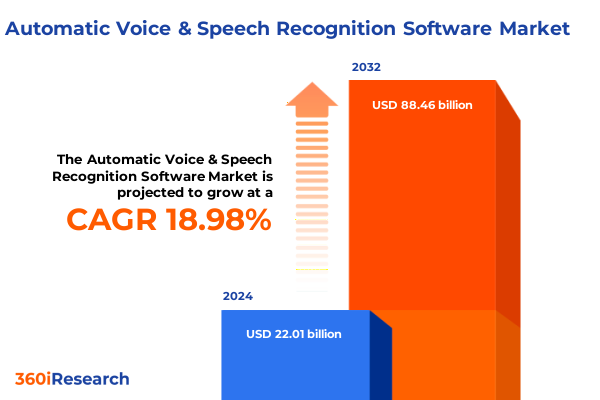
自動音声認識ソフトウェア市場は、人間言語とデジタルシステムを前例のない方法で橋渡しする技術変革の最前線に立っています。2024年には220.1億ドルと推定された市場規模は、2025年には262.0億ドルに達し、その後2032年までに884.6億ドルへと成長すると予測されており、2025年から2032年にかけて年平均成長率(CAGR)18.98%という顕著な拡大が見込まれています。この成長は、ディープラーニングや高度なニューラルネットワークアーキテクチャの活用によって推進されており、現代の音声認識プラットフォームは、初期の粗雑な音素マッチングから、文脈と意図を理解する洗練されたエンドツーエンドモデルへと急速に進化しました。例えば、TransformerベースのASRモデルは、LibriSpeechデータセットにおいて2.2%という低い単語誤り率を達成し、制御された環境下でのシステムがほぼ人間と同等の精度を持つことを示しています。また、話者分離と認識を分離する革新的なアプローチにより、複雑な会話シナリオでも約5.1%の誤り率で優れたマルチスピーカー性能を発揮しています。
市場は、機械学習ベース認識、ディープラーニングベース認識、自然言語処理(NLP)といった技術、クラウドベースとオンプレミスという展開タイプ、さらに機能、アプリケーション、エンドユーザー産業によって多角的にセグメント化されています。企業は、業務の効率化、顧客エンゲージメントの強化、手動転写への依存度低減のために音声インターフェースを統合しており、顧客サービスからヘルスケア、自動車に至るまで、様々な産業で音声駆動型アプリケーションの採用が従来のワークフローを再構築しています。コンタクトセンターでは通話ルーティングと感情分析が自動化され、医療機関では正確なカルテ作成とコンプライアンスのために音声テキスト変換ソリューションが導入されています。組織が効率性の向上とより豊かなユーザーエクスペリエンスの両方を追求する中で、自動音声認識ソフトウェアはデジタルトランスフォーメーションの極めて重要な実現者として浮上しています。
### 成長ドライバー
自動音声認識ソフトウェア市場の成長は、主にAIアーキテクチャ、自己教師あり学習、エッジファーストのプライバシー重視型展開における画期的な進歩によって推進されています。
1. **AIアーキテクチャと機械学習の革新:**
* **自己教師あり学習:** ラベル付けされていない大量の音声データを活用できる自己教師あり学習技術は、高コストなアノテーション付きデータセットへの依存を最小限に抑え、計り知れない可能性を解き放ちました。これにより、モデルはより広範なデータから学習し、汎用性と堅牢性を向上させることができます。
* **エンドツーエンドTransformerモデル:** 現在のエンドツーエンドTransformerモデルは、単に音声を転写するだけでなく、意味的および文脈的洞察を抽出することが可能であり、より自然な会話型AIへの道を開いています。例えば、オープンソースシステムであるWhisper large-v2は、多様なデータセットで2.9%近い単語誤り率を達成し、規模と事前学習の力を示しています。
* **精度向上:** TransformerベースのASRモデルや、話者分離と認識を分離するアプローチは、それぞれ2.2%および5.1%といった低い単語誤り率を達成し、システムがほぼ人間と同等の精度を持つことを実証しています。
2. **エッジコンピューティングとの融合とプライバシー重視の展開:**
* 音声AIとエッジコンピューティングの融合は、展開戦略とプライバシーパラダイムを再構築しています。エッジベースの推論は、レイテンシを削減し、機密性の高い音声データがクラウドに転送される量を制限します。これは、EUの一般データ保護規則(GDPR)やカリフォルニア州消費者プライバシー法(CCPA)といった厳格な規制に合致するものです。これらの規制は、音声を生体認証データまたは個人データとして分類し、厳格な同意および削除要件を課しています。
* 結果として、組織は、パフォーマンスとコンプライアンスの両方を確保するために、集中型モデル更新とオンデバイス処理のバランスを取るハイブリッドアーキテクチャを採用しています。
3. **ビジネスプロセスの変革と効率化:**
* 自動音声認識ソフトウェアは、顧客エンゲージメントの向上、運用効率の改善、手作業による転写の削減を通じて、ビジネスプロセスに革命をもたらしています。
* **顧客サービス:** コンタクトセンターでは、インテリジェントなルーティングと分析のために自然言語理解を活用した通話自動化や感情分析が導入されています。
* **ヘルスケア:** 医療機関では、正確なカルテ作成とコンプライアンスのために音声テキスト変換ソリューションが利用されています。
* **その他の産業:** 自動車分野では音声駆動型アプリケーションが、法律や医療、一般的な分野ではディクテーションや転写が、文書作成ワークフローを加速させています。バーチャルアシスタントは個人および顧客サービスの両方でサポートを提供し、音声生体認証は話者識別と検証に利用されています。
* これらのアプリケーションは、企業が効率性の向上とより豊かなユーザーエクスペリエンスを追求する上で、自動音声認識ソフトウェアがデジタルトランスフォーメーションの極めて重要な実現者であることを示しています。
### 市場の展望
自動音声認識ソフトウェア市場は、技術的進歩とビジネスニーズの進化に牽引され、今後もダイナミックな変化を遂げると予測されます。しかし、いくつかの課題と戦略的な考慮事項が存在します。
1. **市場の課題と考慮事項:**
* **関税の影響:** 2025年に米国で実施されたセクション301関税の累積的な影響は、特にハードウェアに依存するセグメントにおいて、自動音声認識ソフトウェアのエコシステムに新たな考慮事項をもたらしています。米国通商代表部(USTR)による半導体輸入関税の50%への引き上げは、オンプレミスサーバーとエッジデバイスの両方に不可欠な音声処理チップのコストを押し上げています。同時に、多結晶シリコンおよび太陽電池ウェハー部品への関税50%、タングステン製品への関税25%の引き上げは、再生可能エネルギーソリューションを動力源とするクラウドデータセンターインフラのサプライチェーンにさらなる圧力をかけています。この投入コストの上昇は、一部の企業にハードウェアのアップグレードや拡張計画の遅延を促しています。企業は、関税の不確実性の下での投資に躊躇しており、政策目標と運用上の機敏性の間の緊張が浮き彫りになっています。
* **対策:** 企業は、高騰する関税の財政的影響を軽減し、音声AI展開の費用対効果とスケーラビリティを確保するために、部品調達の多様化とソフトウェア最適化への依存度を高めることを模索しています。
2. **詳細な市場セグメンテーションの動向:**
* **アプリケーション:** コールセンター自動化(インテリジェントルーティング、分析)、ディクテーション・転写(法律、医療、一般分野での文書作成加速)、バーチャルアシスタント(個人および顧客サービスサポート)、音声生体認証(話者識別と検証)が主要な応用分野です。
* **コンポーネント:** ハードウェアは性能とレイテンシを支える基盤ですが、ソフトウェアおよび関連するコンサルティング、統合、サポートサービスが、カスタマイズと継続的な最適化を通じて価値の大部分を占めています。
* **展開タイプ:** クラウド(パブリック、プライベート、ハイブリッド)とオンプレミス間の選択は、データ制御、スケーラビリティ、統合の複雑さに影響を与えます。
* **エンドユーザー産業:** 自動車・交通(車載音声コマンド、交通管理システム)、BFSI(不正検知、顧客サービス)、ヘルスケア(臨床文書作成)、小売・Eコマース(大規模顧客サポート)、通信・IT(ネットワーク管理、顧客インタラクションプラットフォーム)など、多岐にわたる垂直市場で採用が進んでいます。
3. **地域別の採用パターン:**
* **南北アメリカ:** 北米では、堅牢なクラウドエコシステムと規制の明確さを活用した大規模展開が先行しています。ブラジルとメキシコも、コールセンターの効率化と多言語顧客サポートのために音声分析を導入しています。
* **EMEA(欧州、中東、アフリカ):** 英国、ドイツ、北欧諸国では、データ主権とプライバシーコンプライアンスを優先するデジタルトランスフォーメーションイニシアチブが、プライベートおよびハイブリッドクラウドソリューションへの需要を刺激しています。湾岸協力会議(GCC)諸国は、音声対応の交通管理システムや公共安全システムを統合する政府主導のスマートシティプログラムに注力しています。
* **アジア太平洋:** 中国はコールセンターや公共サービス全体でのAI統合を政府が義務付けており、日本と韓国は低レイテンシのエッジ音声アプリケーションの研究開発を重視しています。インドの多言語環境は、地域言語の転写におけるイノベーションを促進し、専門モデルの機会を創出しています。東南アジア市場も、識字率の障壁を克服し、金融包摂イニシアチブを支援するために音声インターフェースの採用を加速させています。
4. **競争環境:**
* **ハイパースケーラー:** Amazon Transcribe、Microsoft Azure Speech Services、Google(広範なAIスタックへの統合)、IBM Watson Speech to Text(エンタープライズセキュリティと分析プラットフォームとの統合)などが、コア音声サービスを推進しています。
* **専門プロバイダー:** DeepgramのNova-3モデルは、ストリーミングシナリオで7%未満の単語誤り率を達成し、ヘルスケア向けに特化したバリアントで高い精度向上を実現しています。Sensoryはオフラインアプリケーション向けの低フットプリントSDKを提供し、Nuance(現在はMicrosoft傘下)はヘルスケア転写セグメントを支配しています。VerintやNICEのようなツールは、顧客エンゲージメントのための会話分析に注力しています。
* **サービスプロバイダーとシステムインテグレーター:** これらは、業界固有のワークフローに合わせてコアエンジンを適応させ、エンタープライズ規模でのシームレスな展開を保証する上で重要な役割を果たしています。
5. **エグゼクティブ向け戦略的ロードマップ:**
* 業界リーダーは、スケーラビリティ、レイテンシ、コンプライアンス要件のバランスを取るために、集中型モデルトレーニングとエッジベースの推論を組み合わせたハイブリッドクラウド戦略を優先すべきです。
* 医療や法律転写などのニッチなアプリケーションで精度を高めるためには、ドメイン固有のモデル微調整への投資が不可欠です。
* 通信キャリアやOEMとのパートナーシップは、車載およびネットワーク管理の統合ユースケースを解き放つことができます。
* 関税変動によるサプライチェーンリスクを軽減するためには、ハードウェア調達の多様化、ソフトウェア最適化の活用、エンドユーザーに近い場所での計算資源の地理的配置を検討する必要があります。
* プライバシー・バイ・デザインの原則を組み込むことで、ユーザーの信頼を築き、法域を超えたコンプライアンスを簡素化できます。具体的には、きめ細かな同意メカニズム、堅牢な匿名化、明確なデータ保持ポリシーを導入することで、企業は進化する規制に対応しつつ、イノベーションの速度を維持することが可能です。
* 最後に、オープンAPIとSDKを通じてサードパーティ開発者のエコシステムを育成することは、ソリューションの採用を加速させ、新たな収益源を創出するでしょう。
自動音声認識ソフトウェア市場は、技術革新、ビジネスプロセスの変革、そして戦略的な市場アプローチによって、今後も持続的な成長と進化を遂げるでしょう。
以下に、提供された情報に基づき、詳細な階層構造を持つ日本語の目次を構築します。
—
## 目次
**I. 序文**
* 市場セグメンテーションとカバレッジ
* 調査対象期間
* 通貨
* 言語
* ステークホルダー
**II. 調査方法**
**III. エグゼクティブサマリー**
**IV. 市場概要**
**V. 市場インサイト**
* レイテンシー削減とプライバシー強化のための音声認識におけるオンデバイスエッジ処理の統合
* 多言語音声認識精度向上のための高度な深層学習トランスフォーマーアーキテクチャの採用
* ユーザーデータプライバシー保護と音声モデルパーソナライズのための連合学習フレームワークの利用
* 騒がしい環境でのエラー率低減のためのエンドツーエンドニューラル音声認識パイプラインの実装
* 金融・ヘルスケア産業におけるセキュアな認証のためのリアルタイム音声バイオメトリクスの需要増加
* より自然なユーザーインタラクションのための感情・センチメント分析機能を備えた音声アシスタントの拡大
* コールセンターのパフォーマンスと顧客センチメントインサイトのための音声駆動型分析プラットフォームの出現
* 少数言語方言における音声認識をサポートするための低リソース言語モデルの開発
**VI. 2025年米国関税の累積的影響**
**VII. 2025年人工知能の累積的影響**
**VIII. 自動音声認識ソフトウェア市場、技術別**
* 機械学習ベース認識
* 深層学習ベース認識
* 自然言語処理 (NLP)
* ハイブリッドシステム
**IX. 自動音声認識ソフトウェア市場、展開タイプ別**
* クラウドベース
* オンプレミス
**X. 自動音声認識ソフトウェア市場、機能別**
* 音声認識
* 声紋認識
* 音声コマンド処理
* 音声分析
**XI. 自動音声認識ソフトウェア市場、用途別**
* 音声コマンド
* 文字起こし
* 音声分析
* バーチャルアシスタント
**XII. 自動音声認識ソフトウェア市場、エンドユーザー産業別**
* ヘルスケア
* 自動車
* 家庭用電化製品
* BFSI (金融サービス・保険)
* 小売・Eコマース
**XIII. 自動音声認識ソフトウェア市場、地域別**
* 米州
* 北米
* ラテンアメリカ
* 欧州、中東、アフリカ
* 欧州
* 中東
* アフリカ
* アジア太平洋
**XIV. 自動音声認識ソフトウェア市場、グループ別**
* ASEAN (東南アジア諸国連合)
* GCC (湾岸協力会議)
* 欧州連合
* BRICS (ブリックス)
* G7 (主要7カ国)
* NATO (北大西洋条約機構)
**XV. 自動音声認識ソフトウェア市場、国別**
* 米国
* カナダ
* メキシコ
* ブラジル
* 英国
* ドイツ
* フランス
* ロシア
* イタリア
* スペイン
* 中国
* インド
* 日本
* オーストラリア
* 韓国
**XVI. 競争環境**
* 市場シェア分析、2024年
* FPNVポジショニングマトリックス、2024年
* 競合分析
* Nuance Communications, Inc.
* Microsoft Corporation
* Google LLC
* Apple Inc.
* Amazon.com, Inc.
* International Business Machines Corporation
* Sensory, Inc.
* ReadSpeaker Holding B.V.
* LumenVox LLC
* OpenAI, L.L.C.
* Verint Systems Inc.
* VoiceVault Inc.
* VoiceBase, Inc.
* Speechmatics Ltd.
* Acapela Group SA
* Cerence Inc.
—
### 図表リスト [合計: 30]
1. 世界の自動音声認識ソフトウェア市場規模、2018-2032年 (百万米ドル)
2. 世界の自動音声認識ソフトウェア市場規模、技術別、2024年対2032年 (%)
3. 世界の自動音声認識ソフトウェア市場規模、技術別、2024年対2025年対2032年 (百万米ドル)
4. 世界の自動音声認識ソフトウェア市場規模、展開タイプ別、2024年対2032年 (%)
5. 世界の自動音声認識ソフトウェア市場規模、展開タイプ別、2024年対2025年対2032年 (百万米ドル)
6. 世界の自動音声認識ソフトウェア市場規模、機能別、2024年対2032年 (%)
7. 世界の自動音声認識ソフトウェア市場規模、機能別、2024年対2025年対2032年 (百万米ドル)
8. 世界の自動音声認識ソフトウェア市場規模、用途別、2024年対2032年 (%)
9. 世界の自動音声認識ソフトウェア市場規模、用途別、2024年対2025年対2032年 (百万米ドル)
10. 世界の自動音声認識ソフトウェア市場規模、エンドユーザー産業別、2024年対2032年 (%)
11. 世界の自動音声認識ソフトウェア市場規模、エンドユーザー産業別、2024年対2025年対2032年 (百万米ドル)
12. 世界の自動音声認識ソフトウェア市場規模、地域別、2024年対2025年対2032年 (百万米ドル)
13. 米州の自動音声認識ソフトウェア市場規模、サブ地域別、2024年対2025年対2032年 (百万米ドル)
14. 北米の自動音声認識ソフトウェア市場規模、国別、2024年対2025年対2032年 (百万米ドル)
15. ラテンアメリカの自動音声認識ソフトウェア市場規模、国別、2024年対2025年対2032年 (百万米ドル)
16. 欧州、中東、アフリカの自動音声認識ソフトウェア市場規模、サブ地域別、2024年対2025年対2032年 (百万米ドル)
17. 欧州の自動音声認識ソフトウェア市場規模、国別、2024年対2025年対2032年 (百万米ドル)
18. 中東の自動音声認識ソフトウェア市場規模、国別、2024年対2025年対2032年 (百万米ドル)
19. アフリカの自動音声認識ソフトウェア市場規模、国別、2024年対2025年対2032年 (百万米ドル)
20. アジア太平洋の自動音声認識ソフトウェア市場規模、国別、2
………… (以下省略)
*** 本調査レポートに関するお問い合わせ ***

自動音声認識ソフトウェア(ASR)は、人間の発話をデジタルデータとして認識し、テキスト情報に変換する技術であり、現代社会におけるヒューマンコンピュータインタラクションの根幹をなす重要な要素技術の一つである。スマートフォンに搭載された音声アシスタントから、コールセンターの自動応答システム、さらには医療現場での記録作成に至るまで、その応用範囲は広がり、私たちの日常生活やビジネスのあり方を劇的に変えつつある。このソフトウェアは、単なる音声変換に留まらず、その背後にある複雑な言語処理と機械学習の粋を集めた技術である。
その動作原理は、複数の段階を経て実現される。まず、マイクを通じて捕捉されたアナログ音声信号はデジタルデータに変換され、人間の聴覚特性を模倣した特徴量(例えば、メル周波数ケプストラム係数:MFCC)が抽出される。これらの特徴量は、音響モデルに入力され、特定の音素や単語が発話された確率が計算される。音響モデルは、大量の音声データとそれに対応するテキストデータを用いて学習されており、発話された音と文字の対応関係を学習する。同時に、言語モデルは、単語の並びの自然さや文法的な妥当性を評価し、最も可能性の高い単語列を予測する。初期のシステムでは隠れマルコフモデル(HMM)が主流であったが、近年では深層学習(DNN、RNN、Transformerなど)の導入により、認識精度が飛躍的に向上した。
自動音声認識技術の歴史は、1950年代にベル研究所で単一話者による数字の認識が試みられたことに端を発する。その後、1980年代から1990年代にかけては、統計的手法である隠れマルコフモデル(HMM)が主流となり、認識精度の向上に大きく貢献した。2000年代に入ると、計算能力の向上と大規模な音声データの利用が可能となり、より複雑なモデルの学習が進んだ。そして、2010年代以降、深層学習、特にディープニューラルネットワーク(DNN)の登場は、この分野に革命をもたらした。これにより、従来のモデルでは困難であった多様な発話スタイルや環境ノイズ下での認識能力が格段に向上し、実用レベルでの普及が加速したのである。
このソフトウェアは、その特性によっていくつかの種類に分類できる。一つは、特定の話者の声に特化して学習する「話者依存型」と、不特定多数の話者の声を認識できる「話者独立型」である。また、認識する語彙の規模によって「小語彙認識」と「大語彙認識」に分けられ、前者は特定のコマンド認識などに、後者は自由な会話の認識に用いられる。さらに、単語ごとに区切って発話する「孤立単語認識」と、自然な流れで発話される「連続音声認識」があり、現代の主流は後者である。近年では、クラウドベースのサービスとして提供されるものが一般的だが、プライバシー保護やリアルタイム性を重視する用途では、デバイス上で直接処理を行う「オンデバイス認識」の需要も高まっている。
自動音声認識ソフトウェアの応用分野は多岐にわたる。最も身近な例としては、AppleのSiri、AmazonのAlexa、Googleアシスタントといった音声アシスタントが挙げられ、情報検索やデバイス操作、スマートホーム機器の制御などを行う。ビジネス分野では、コールセンターにおける顧客対応の自動化や、オペレーター支援、会議の議事録作成、医療現場での電子カルテ入力支援などに活用されている。その他、障がい者支援ツールとしての字幕生成や、外国語学習アプリでの発音評価、自動車のインフォテインメントシステムやスマート家電への組み込み、さらには声紋による生体認証など、その利用範囲は広がり続けている。
しかしながら、自動音声認識技術には依然としていくつかの課題が存在する。最も顕著なのは、認識精度に関する問題である。背景ノイズの多い環境、複数の話者が同時に発話する状況、方言やアクセント、早口や不明瞭な発話など、現実世界の多様な音声環境下では、依然として誤認識が発生しやすい。また、単語の認識はできても、その文脈や発話者の意図を正確に理解する「意味理解」の壁は高く、自然言語処理技術とのさらなる連携が不可欠である。プライバシー保護も重要な課題であり、音声データがどのように収集、処理、保存されるかについての透明性とセキュリティの確保が求められる。さらに、多様な言語や文化に対応するための大規模な学習データと計算資源の確保も、グローバルな展開における課題となっている。
将来的に、自動音声認識ソフトウェアはこれらの課題を克服し、さらに高度な機能を持つようになるだろう。認識精度は継続的に向上し、あらゆる環境下でのロバスト性が強化されると予測される。また、単なる音声のテキスト変換に留まらず、感情認識や話者識別、さらには発話者の意図を深く理解し、より自然で人間らしい対話を実現する方向へと進化する。エッジコンピューティングの発展により、デバイス上での高速かつプライバシーに配慮した処理が可能になり、よりパーソナライズされたサービスが提供されるようになる。音声認識は、視覚、触覚といった他のモダリティと融合し、より直感的で豊かなマルチモーダルインタラクションの基盤を築くこととなるだろう。自動音声認識ソフトウェアは、私たちの生活と社会をより豊かに、より便利にするための不可欠な技術として、その進化の歩みを止めることはない。